How to Design a URL Shortener: The System Design Interview Deep Dive

"Design a URL shortener" is the perfect litmus test for senior engineering candidates. It seems deceptively simple - take a long URL, make it short. But the depth of your answer reveals everything about your ability to build distributed systems at scale.
TL;DR
A URL shortener system design interview tests your ability to build distributed systems, not just string manipulation. Start with requirements clarification and back-of-the-envelope math (100M URLs/month, 100:1 read-write ratio, 40K peak reads/sec). Use base62 encoding or hash-based generation for short codes, SQL for URL storage with NoSQL for analytics, and multi-layer caching (local, Redis, database) to handle the power-law traffic distribution. Scale horizontally with consistent hashing, deploy across multiple geographic regions, and separate synchronous URL creation from asynchronous click tracking. The strongest candidates demonstrate clear trade-off reasoning rather than memorized architectures.
I had a candidate once who started with "I'll just use a hash function and a database." Twenty minutes later, we were discussing geographic data replication, cache invalidation strategies, and how to handle 100,000 requests per second. That's the beauty of this problem - it scales with the candidate's experience and leads to very interesting discussions.
The Problem: More Than Just Shortening URLs
When an interviewer asks you to design a URL shortener like bit.ly or TinyURL, they're not really interested in the string manipulation. They want to see if you can build a system that handles billions of URLs while serving millions of users globally with sub-100ms response times. The question seems straightforward, but it opens doors to discussions about distributed systems, database design, caching strategies, and handling failure at scale.
What makes this problem particularly interesting is that every engineer has used a URL shortener, but few have thought about what happens behind that simple redirect. Your interviewer is evaluating whether you can think systematically about large-scale problems, whether you understand the implications of serving traffic at different scales, and most importantly, whether you can make intelligent trade-offs between competing concerns like consistency and availability. They want to know if you've actually built systems that serve real traffic, or if you're just reciting theoretical knowledge.
Step 1: Clarifying Requirements

The best candidates don't jump straight into the solution. They start by understanding what they're actually building. I always appreciate when someone takes a step back and asks clarifying questions - it shows they've learned from real-world experience where requirements are rarely clear from the start.
For a URL shortener, you need to understand both the functional and non-functional requirements. Functionally, the system needs to take long URLs and convert them to short codes (typically 6-8 characters like bit.ly/abc1234), redirect users from short URLs to their original destinations, and ideally track analytics for each click. Some systems also support custom aliases where users can choose their own short code, and URL expiration for temporary links.
The non-functional requirements are where things get interesting. Let's say you're designing for 100 million new URLs per month. That breaks down to about 40 URLs per second on average, but you know traffic isn't uniform - you might see 10x that during peak hours. More importantly, URL shorteners typically see a 100:1 read to write ratio, meaning for every new URL created, it gets accessed 100 times. So while you're writing 40 URLs per second, you're serving 4000 redirects per second.
Back-of-the-envelope calculations:
- Storage: 100M URLs/month × 500 bytes/URL = 50GB/month = 600GB/year
- Bandwidth: 4000 requests/sec × 500 bytes = 2MB/sec read bandwidth
- Cache size: Top 20% of URLs (Pareto principle) = 20M URLs × 500 bytes = 10GB (fits in memory!)
- QPS at peak: 400 writes/sec, 40,000 reads/sec
These numbers aren't just academic exercises. When you calculate that 100 million URLs with metadata only requires about 300GB of storage per year, you realize this entire dataset could fit in memory on a single high-end server. But when you factor in that you need sub-100ms latency globally and 99.9% availability, suddenly you're designing a distributed system. The bandwidth requirement of 2MB per second seems trivial until you realize that's just the average - during viral social media events, a single shortened URL might get millions of clicks in an hour.
Step 2: High-Level Architecture
When candidates start drawing architecture diagrams, I can immediately tell their level of experience. Junior engineers often jump straight to microservices and Kubernetes. Senior engineers start with a simple design and evolve it based on requirements.
The most basic version of a URL shortener is just a web server talking to a database. A client makes a request, the server either stores a new URL or retrieves an existing one, and returns the result. This design would actually work fine for your first thousand users, maybe even your first hundred thousand if you optimize well. But the interviewer wants to see how you think about scale.
As you add more users, the single server becomes a bottleneck. The natural evolution is to add a load balancer distributing traffic across multiple web servers. Your database, handling both reads and writes, becomes the next bottleneck. You solve this by implementing master-slave replication - writes go to the master, reads are distributed across slaves. But even this isn't enough for a service handling thousands of requests per second.
This is where caching becomes critical. Since URL shorteners have such a skewed access pattern (a small percentage of URLs get the vast majority of traffic), adding a cache layer like Redis can handle 80% of your read traffic without touching the database. For analytics and large data that doesn't need immediate consistency, you might also add an object store like S3.
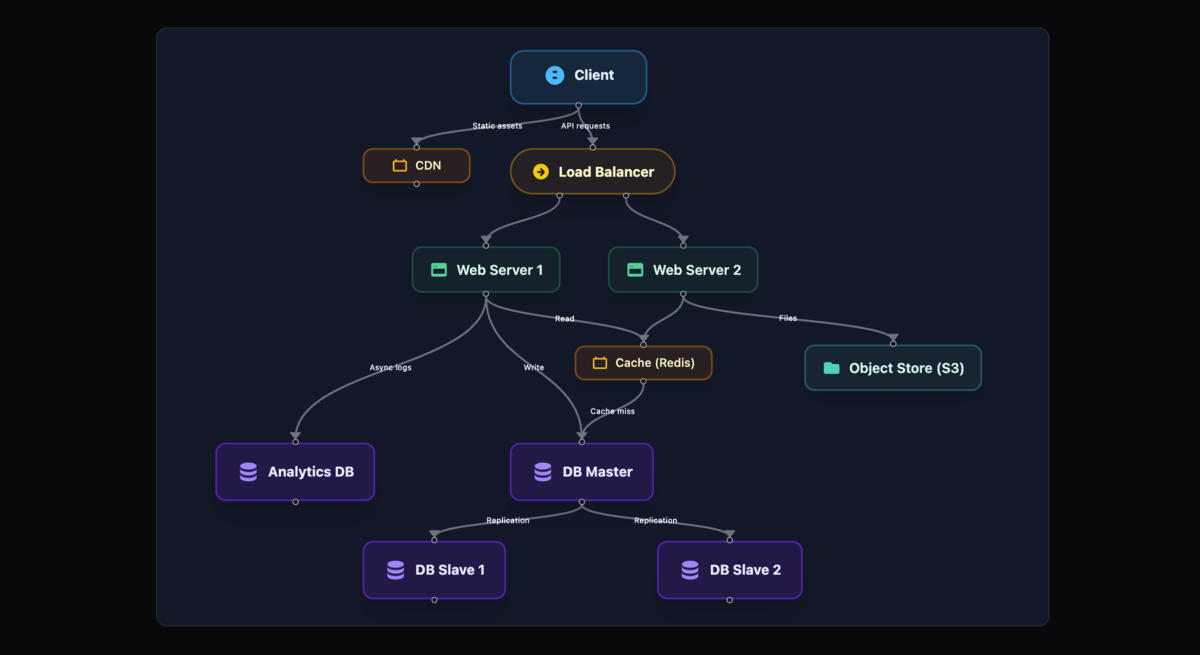
The production-ready system that emerges from these iterations looks something like this:
Loading visualization...
Step 3: Database Schema and Storage

Database design is where I see candidates reveal their real-world experience (or lack thereof). The naive approach is to create a single table with the short URL, long URL, and maybe a click counter. But as soon as you start updating that click counter on every request, you've created a massive bottleneck that will bring your system to its knees under load.
The smarter approach separates concerns. Your main URLs table should contain relatively static data that changes infrequently. Here you store the short URL as your primary key, the long URL it maps to, creation timestamp, optional expiration time, and perhaps the user who created it. The critical insight is that this table is mostly read-heavy after the initial write.
CREATE TABLE urls (
short_url VARCHAR(7) PRIMARY KEY,
long_url TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
expires_at TIMESTAMP,
user_id BIGINT,
custom_alias VARCHAR(50),
INDEX idx_user_id (user_id),
INDEX idx_expires_at (expires_at),
INDEX idx_custom_alias (custom_alias)
);
CREATE TABLE analytics (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
short_url VARCHAR(7),
clicked_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
ip_address VARCHAR(45),
user_agent TEXT,
referer TEXT,
country VARCHAR(2),
INDEX idx_short_url (short_url),
INDEX idx_clicked_at (clicked_at)
);
Analytics deserve their own table, or better yet, their own data pipeline. Every click generates an analytics event with the timestamp, IP address, user agent, referrer, and geographic information. This data is write-heavy and can tolerate eventual consistency. You don't need to know the exact click count in real-time; being a few seconds behind is perfectly acceptable.
The question of SQL versus NoSQL always comes up, and the answer isn't as clear-cut as you might think. For the core URL mappings, SQL databases actually make more sense. You have a well-defined schema, you need ACID properties to ensure URL uniqueness, and the dataset is small enough to fit in a single database for a long time. Where NoSQL shines is in the analytics pipeline - systems like Cassandra are built for high-volume writes and can handle the fire hose of click events without breaking a sweat.
Step 4: URL Generation Algorithms

Now we get to the heart of the technical challenge: how do you generate those 7-character short codes? This is where candidates often get lost in complexity, but there are really only three viable approaches, each with distinct trade-offs.
The first approach uses a simple counter. You start at 1 and increment for each new URL, converting the number to base62 (using alphanumeric characters) to get your short code. It's beautifully simple - the first URL is "1", the thousandth is "g8", and so on. But this simplicity comes with serious drawbacks. The URLs are predictable, which is a security nightmare. Someone could easily enumerate all your URLs by incrementing through the sequence. Plus, implementing a distributed counter that works across multiple servers without collisions is surprisingly complex.
def generate_short_url(counter):
chars = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
result = []
base = len(chars) # 62
# Convert to base-62
while counter > 0:
result.append(chars[counter % base])
counter //= base
# Pad to minimum length (e.g., 6 characters)
while len(result) < 6:
result.append(chars[0])
return ''.join(reversed(result))
# Examples:
# generate_short_url(1) -> "000001"
# generate_short_url(62) -> "000010"
# generate_short_url(238328) -> "0010Ko"
The hash-based approach, which I personally prefer for most implementations, takes the long URL combined with some unique factors like timestamp and user ID, runs it through a hash function like MD5 or SHA-256, and takes a portion of the hash to create your short code. This gives you random-looking, unpredictable URLs without needing any coordination between servers.
import hashlib
import time
def generate_hash_url(long_url, attempt=0):
chars = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
# Combine URL with timestamp and attempt counter for uniqueness
unique_string = f"{long_url}{time.time()}{attempt}"
hash_value = hashlib.md5(unique_string.encode()).hexdigest()
# Convert first 8 hex chars to base-62 (gives us ~6-7 chars)
num = int(hash_value[:8], 16)
result = []
while num > 0 and len(result) < 7:
result.append(chars[num % 62])
num //= 62
return ''.join(result[::-1])
Each server can independently generate URLs without worrying about collisions. With 62^7 possible combinations (3.5 trillion), the probability of collision is low enough that you can handle them when they occur by simply regenerating with a different seed.
The third approach uses a distributed ID generation service, similar to Twitter's Snowflake (which generates unique 64-bit IDs) or Instagram's ID generation strategy. Companies like Uber (with their distributed ID generator), Pinterest, and Discord all use variations of this approach. The core idea is to have dedicated servers that generate guaranteed-unique IDs using a combination of timestamp, machine ID, and sequence number. For URL shorteners specifically, you might pre-generate millions of unique 7-character keys and store them in a pool. When you need a new short URL, you just grab an unused key from this pool - no collision checking required.
This approach is particularly popular at companies dealing with massive scale. Instagram uses a similar strategy for their media IDs, encoding a timestamp, shard ID, and sequence number into each ID. Discord modified Snowflake for their message IDs to ensure chronological ordering across distributed systems. The trade-off is operational complexity - you need to maintain another highly available service. If your key generation service goes down, you can't create new URLs. But at the scale of billions of URLs, the guaranteed uniqueness without any coordination between application servers makes this complexity worthwhile.
Fun fact: Designing a distributed unique ID generation service is itself a fascinating system design problem that comes up in interviews. How do you generate IDs that are unique across hundreds of servers without any coordination? How do you ensure they're roughly sortable by time? What happens during clock skew? We'll dive deep into this problem in a future post.
Step 5: Scaling to Millions of Users

This is where the conversation gets really interesting, and where senior engineers distinguish themselves from juniors who've only read about distributed systems in blog posts.
Database scaling is your first major challenge. When your single database can't handle the load anymore, you have several options. The most straightforward is vertical partitioning - separating your tables across different databases based on access patterns. URLs go in one database, analytics in another, user data in a third. This works well because these datasets have different characteristics and scaling needs.
Loading visualization...
But eventually, even individual tables become too large. That's when you need horizontal partitioning, or sharding. For a URL shortener, you have several sharding strategies:
Range-based sharding: URLs starting with 'a' through 'f' go to shard 1, 'g' through 'm' to shard 2, etc. Simple but can lead to uneven distribution.
Hash-based sharding: Take hash(short_url) % num_shards. More even distribution but loses locality.
Consistent hashing: Allows adding/removing shards with minimal data movement. Used by Cassandra and DynamoDB.
The challenge with any sharding strategy is handling hotspots - what if one particularly viral URL gets millions of requests? Solutions include:
- Hot partition splitting: Dynamically split overwhelmed shards
- Request coalescing: Batch multiple requests for the same URL
- Aggressive caching: Keep viral URLs in memory across all servers
Replication adds another layer of complexity. You'll have a master database for writes and multiple slaves for reads. But here's the catch that trips up many candidates: replication lag. When you write a new URL to the master, it takes time to replicate to the slaves. If a user creates a short URL and immediately tries to use it, the read might hit a slave that hasn't received the update yet. The solution? Read from the slave first, but if you don't find the URL and it was created recently (say, within the last 5 seconds), fall back to reading from the master.
Caching is where you can make or break your system's performance. The key insight is that URL access follows a power law distribution - 20% of your URLs will get 80% of the traffic. This means aggressive caching of popular URLs can dramatically reduce your database load.
I like to think of caching in layers. Your first layer is application memory - keep the hundred most popular URLs right in your web server's memory. Access time: maybe 1 millisecond. The second layer is a distributed cache like Redis, which might hold a million URLs. Access time: 10-50 milliseconds depending on network latency. The third layer is your database, which has everything but might take 100+ milliseconds to query.
Loading visualization...
import time
from functools import lru_cache
class URLCache:
def __init__(self, redis_client, db_client):
self.redis = redis_client
self.db = db_client
self.local_cache = {} # Or use @lru_cache
def get_long_url(self, short_url):
# Level 1: Local memory (< 1ms)
if short_url in self.local_cache:
entry = self.local_cache[short_url]
if entry['expires'] > time.time():
return entry['url']
# Level 2: Redis distributed cache (10-50ms)
cached_url = self.redis.get(short_url)
if cached_url:
# Refresh local cache
self.local_cache[short_url] = {
'url': cached_url,
'expires': time.time() + 300 # 5 min local TTL
}
return cached_url
# Level 3: Database (50-200ms)
url = self.db.query(
"SELECT long_url FROM urls WHERE short_url = %s",
(short_url,)
)
if url:
# Populate both cache layers
self.redis.setex(short_url, 3600, url) # 1 hour Redis TTL
self.local_cache[short_url] = {
'url': url,
'expires': time.time() + 300
}
return url
But caching introduces its own challenges. Cache invalidation is famously one of the two hard problems in computer science (along with naming things and off-by-one errors). When do you evict URLs from cache? How do you handle cache stampedes when a popular URL's cache entry expires and thousands of requests hit your database simultaneously?
Cache stampede solutions:
- Probabilistic early expiration: Randomly refresh cache before actual expiry
- Lock-based refresh: First request refreshes while others wait
- Background refresh: Proactively refresh popular entries before expiry
def get_with_stampede_protection(self, key):
value = self.cache.get(key)
expiry = self.cache.ttl(key)
# Probabilistic early refresh
if value and expiry > 0:
# XFetch algorithm: refresh probability increases as expiry approaches
beta = 1.0 # Tunable parameter
now = time.time()
x_fetch = expiry - beta * math.log(random.random())
if now >= x_fetch:
# Refresh cache in background
self.refresh_cache_async(key)
return value
Geographic distribution is essential for a global service. You can't serve users in Sydney from a single datacenter in Virginia and expect good performance. The speed of light is finite, and every millisecond counts.

The standard approach is to deploy your service in multiple regions - US East, US West, Europe, Asia Pacific at minimum. GeoDNS routes users to their nearest datacenter, reducing latency from potentially 200+ milliseconds to under 50. But this creates new challenges: how do you keep data synchronized across regions?
The clever approach is to recognize that not all data needs to be everywhere. Popular URLs that go viral should be replicated globally - everyone might need quick access to them. But user-specific URLs (like private share links) can stay in the region where they were created. This selective replication reduces your data transfer costs and synchronization complexity while maintaining good performance for the majority of requests.
Step 6: Edge Cases and Failure Modes
The best interviews aren't just about the happy path. They're about what happens when things go wrong or when users do unexpected things. These edge cases are where you show you've actually built and operated production systems.
Consider what happens when two users try to shorten the same URL. The naive approach would create two different short codes pointing to the same destination. But that's wasteful and reduces cache efficiency. The better approach is to return the same short URL to both users, but this requires careful implementation:
def create_short_url(self, long_url, user_id=None, custom_alias=None):
# Check if URL already exists (for deduplication)
existing = self.db.query(
"SELECT short_url FROM urls WHERE long_url = %s AND user_id IS NULL",
(long_url,)
)
if existing and not custom_alias:
# Return existing public short URL
return existing[0]
# Generate new short URL
max_retries = 5
for attempt in range(max_retries):
if custom_alias:
short_url = custom_alias
else:
short_url = self.generate_hash_url(long_url, attempt)
try:
# Try to insert (will fail if duplicate)
self.db.execute(
"""INSERT INTO urls (short_url, long_url, user_id, created_at)
VALUES (%s, %s, %s, NOW())""",
(short_url, long_url, user_id)
)
return short_url
except DuplicateKeyError:
if custom_alias:
raise AliasAlreadyExistsError()
# For hash collision, retry with different seed
continue
raise URLGenerationError("Failed to generate unique URL")
This deduplication saves storage and improves cache hit rates since popular URLs only have one short code to cache. Of course, this means you need to handle privacy concerns - you might not want to deduplicate private or authenticated URLs.
Custom aliases add another layer of complexity. Users want memorable URLs like "bit.ly/my-resume" instead of "bit.ly/x7Fg9Kl". You need a reservation system to check availability, handle conflicts, and prevent abuse. Someone will inevitably try to claim "bit.ly/google" and redirect it to a phishing site. This brings us to security.
Malicious URLs are a real problem for any URL shortener. You're essentially running an open redirect service, which attackers love for phishing campaigns. Integration with URL reputation services like Google Safe Browsing is essential. But you can't check every URL synchronously - that would add hundreds of milliseconds to your response time. Instead, you check asynchronously and use temporary redirects initially, converting to permanent redirects only after the URL passes security checks.
Rate limiting is crucial to prevent abuse. But it's more nuanced than just "X requests per minute." You need a multi-layered approach:
class RateLimiter:
def __init__(self, redis_client):
self.redis = redis_client
self.limits = {
'create_url': {'per_minute': 10, 'per_hour': 100, 'per_day': 500},
'redirect': {'per_minute': 1000, 'per_hour': 50000},
'api_call': {'per_minute': 60, 'per_hour': 1000}
}
def check_rate_limit(self, user_id, action, ip_address):
# Multiple rate limit buckets
buckets = [
(f"rl:user:{user_id}:{action}", self.limits[action]),
(f"rl:ip:{ip_address}:{action}", self.limits[action]),
(f"rl:global:{action}", {'per_minute': 10000}) # Global limit
]
for bucket_key, limits in buckets:
for window, limit in limits.items():
window_seconds = self._get_window_seconds(window)
current = self.redis.incr(f"{bucket_key}:{window}")
if current == 1:
self.redis.expire(f"{bucket_key}:{window}", window_seconds)
if current > limit:
return False, f"Rate limit exceeded: {limit} per {window}"
return True, None
def _get_window_seconds(self, window):
return {
'per_minute': 60,
'per_hour': 3600,
'per_day': 86400
}[window]
I've seen systems brought down by someone using a URL shortener as a free database, creating millions of URLs with data encoded in them. Progressive delays and exponential backoff help prevent this abuse.
Step 7: Observability and Analytics
Here's a truth I learned the hard way: you can have the most elegant system design in the world, but if you can't observe what it's doing in production, you're flying blind. I've seen beautifully architected systems fail catastrophically because engineers couldn't debug issues when they arose.
For a URL shortener, you need to track metrics at multiple levels. Business metrics tell you if your service is successful - how many URLs are being created, how many clicks you're serving, whether usage is growing. System metrics tell you if your service is healthy - response latency at different percentiles (p50, p95, and especially p99), error rates, cache hit ratios. Database metrics warn you of impending problems - slow queries, replication lag, connection pool exhaustion.
But metrics are only useful if someone's watching them. You need dashboards that surface problems quickly and alerts that fire before users notice issues. Your dashboard should show real-time request rates, latency trends, and cache performance. It should highlight anomalies like traffic spikes to particular URLs (might be viral content or might be an attack) or degraded performance in specific regions.
The alerting strategy is crucial. Alert fatigue is real - if you page engineers for every minor issue, they'll start ignoring alerts. Focus on user-visible problems: error rates above 1%, p99 latency above 500ms, cache hit rate below 70%. Everything else can be a warning that someone looks at during business hours.
The Final Architecture: Putting It All Together
Loading visualization...
Here's what your complete system looks like:
- Client makes request to shorten URL
- CDN serves static content (JS, CSS, images)
- Load Balancer (Layer 7) routes to healthy web servers
- Web Server handles business logic:
- Validates URL
- Generates short code
- Checks cache
- Writes to database
- Cache Layer (Redis Cluster) stores hot URLs
- Primary Database (MySQL/PostgreSQL) handles writes
- Read Replicas handle read traffic
- Analytics Pipeline (Kafka → Spark → Cassandra) processes clicks
- Object Store (S3) stores user data, backups
- Monitoring (Prometheus + Grafana) tracks everything
Making the Right Trade-offs
Every design decision has trade-offs. Here's how to think about them:
The CAP Theorem in Practice
For a URL shortener, you're constantly balancing consistency and availability. When a user creates a short URL, they expect to use it immediately - that demands strong consistency. But when serving redirects, it's better to serve a slightly stale URL than to fail the request entirely.
This leads to a hybrid approach: synchronous replication for URL creation (ensuring the user can immediately use their link), but asynchronous replication for read replicas. If a read replica is behind by a few seconds, you can implement a smart fallback - check the creation timestamp, and if it's within the last 5 seconds, query the master directly. This gives you the best of both worlds: immediate consistency when it matters and high availability for the majority of requests.
Choosing Your Database: SQL vs NoSQL
The SQL versus NoSQL debate often dominates these discussions, but the answer isn't binary. For the core URL mappings, SQL databases make perfect sense. You have a well-defined schema, you need ACID properties to ensure URL uniqueness, and honestly, even a billion URLs is manageable for a well-tuned PostgreSQL instance. Where NoSQL shines is in your analytics pipeline. Systems like Cassandra can handle millions of write operations per second without breaking a sweat, perfect for recording every single click event.
| Aspect | SQL (PostgreSQL/MySQL) | NoSQL (Cassandra/DynamoDB) |
|---|---|---|
| URL Storage | ✓ ACID guarantees, relations | ✗ Eventual consistency |
| Analytics | ✗ Write bottleneck at scale | ✓ High write throughput |
| Scaling | Vertical, then sharding | Horizontal from day one |
| Query Flexibility | ✓ Complex queries possible | ✗ Limited to key lookups |
| Operational Complexity | Lower initially | Higher (distributed system) |
My recommendation? Start with SQL for everything. It's simpler to operate, easier to reason about, and will carry you further than you think. When you hit millions of clicks per day and your analytics writes become a bottleneck, that's when you introduce Cassandra or a similar solution. Don't solve problems you don't have yet.
Synchronous vs Asynchronous Processing
Here's a critical insight: users care about different things at different times. When someone creates a short URL, they want it immediately - that's a synchronous operation. But do they need real-time click counts? Absolutely not. This natural division guides your architecture.
URL creation flows through your main request path: validate the URL, generate the short code, store it in the database, return it to the user. Everything synchronous, everything within a single transaction if possible. But click tracking? That's a fire-and-forget operation. Drop the event into a message queue and return the redirect immediately. Process the analytics in batches every few seconds or minutes. Your users get sub-50ms redirects, and you avoid crushing your database with write operations.
The same principle applies to other features. URL expiration checks? Do them at read time, not with a background job. Malicious URL scanning? Definitely asynchronous - scan after creation and mark as safe or unsafe. Custom domain SSL certificate provisioning? Background job that might take minutes. Understanding what needs to be synchronous versus what can be eventual is crucial for building a performant system.
Common Pitfalls That Tank Interviews

These are the mistakes I see repeatedly that immediately signal a lack of real-world experience. The most common is over-engineering from the start. Candidates jump straight to microservices, Kubernetes, and message queues before establishing basic requirements. Your URL shortener for a startup with 100 users doesn't need the same architecture as bit.ly. Start simple and evolve based on actual needs.
Another frequent mistake is ignoring the numbers. I've had candidates design elaborate caching systems without calculating whether caching even makes sense for their scale. If your entire dataset fits in memory on a single server, maybe you don't need a distributed cache. Conversely, I've seen designs that completely ignore scale, proposing architectures that would crumble under real load.
Many candidates forget about failure modes entirely. They design for the happy path where every service is up, every network call succeeds, and no data is ever corrupted. But in reality, Redis will crash, network partitions will happen, and that critical service will go down at 3 AM on a Sunday. Your design needs to gracefully degrade, not catastrophically fail.
Geographic distribution is often an afterthought, added when the interviewer asks "what about users in other countries?" But serving global traffic requires fundamental architectural decisions. You can't just slap a CDN in front of your US-East datacenter and call it done.
How to Navigate the Interview
Understanding the rhythm of a system design interview is crucial. You have 45 minutes to an hour, and how you use that time matters as much as what you say. The best candidates treat it as a collaborative discussion, not a one-way presentation.
The first five minutes should be spent gathering requirements. Don't just nod along to what the interviewer says - ask clarifying questions. Push back on unrealistic requirements. This shows you're thinking like an engineer who has to actually build the system, not just draw boxes on a whiteboard.
The next ten minutes are for your high-level design. Start simple and iterate. Draw the basic components, explain the data flow, and check if you're on the right track. The interviewer might steer you toward particular areas they want to explore. That's not a bad sign - it means they're engaged and want to see how you think about specific problems.
The meat of the interview, from minute 15 to 35, is detailed component design. This is where you dive deep into database schemas, API designs, and algorithms. Show your work. Explain why you're making certain choices. If you're not sure about something, say so and talk through the options. I'd much rather hear a candidate reason through uncertainty than confidently assert something wrong.
The final ten minutes are usually about optimizations and handling scale. The interviewer might throw curveballs: "What if traffic increases 100x?" or "How would you handle a datacenter failure?" These aren't gotcha questions - they're opportunities to show you can think on your feet and adapt your design to changing requirements.
What We Didn't Cover: Real Production Concerns
The interview version of a URL shortener is necessarily simplified. In the real world, there are dozens of additional considerations that would influence your design. Security becomes paramount when you're running what's essentially an open redirect service. You need rate limiting to prevent abuse, DDoS protection to stay online during attacks, and SSL everywhere to protect user data. You need to scan for malicious URLs, prevent phishing attacks, and deal with bad actors who will inevitably try to abuse your service.
Compliance and legal issues add another layer of complexity. GDPR means European users can demand you delete their data. Content laws vary by country - a URL that's legal in the US might be illegal in Germany. You need data retention policies, audit logs, and the ability to quickly take down problematic content when law enforcement comes knocking.
The business model fundamentally affects your technical architecture. If you're running a freemium service, you need to track usage per user and enforce limits. If you're showing ads, you need to inject them into the redirect flow without adding too much latency. Enterprise customers will want custom domains, detailed analytics, and SLAs that require a much more robust infrastructure.
API design becomes crucial when your URL shortener becomes a platform. Should you offer a RESTful API for simplicity, GraphQL for flexibility, or gRPC for internal service communication? How do you version your APIs without breaking existing integrations? These decisions have long-lasting implications for your system's evolution.
The One Thing That Matters Most
After all the technical discussion, here's the most important thing I've learned from conducting hundreds of interviews: your thinking process matters more than your final answer. I've passed candidates who made technical mistakes but showed excellent problem-solving skills. I've failed candidates with technically perfect designs who couldn't explain their reasoning or adapt when I pushed them in new directions.
The best candidates don't try to impress me with complexity. They start simple, evolve based on requirements, make clear trade-offs, and can defend their decisions. They admit when they don't know something and think out loud through the problem. They ask questions when requirements are unclear and push back when constraints don't make sense.
Key Takeaways
- Start with requirements and math. Calculate storage, bandwidth, and QPS before drawing a single box. Showing you can estimate 100M URLs/month = 40 writes/sec and 4,000 reads/sec demonstrates real engineering judgment.
- Choose the right URL generation strategy for your scale. Base62 counters are simple but hard to distribute; hash-based generation allows independent servers; pre-generated key pools (Snowflake-style) guarantee uniqueness without coordination at massive scale.
- Cache aggressively using the power-law distribution. 20% of URLs attract 80% of traffic. A multi-layer cache (local memory, Redis, database) can serve the vast majority of requests without touching your database at all.
- Separate reads from writes and sync from async. URL creation must be synchronous with strong consistency, but click tracking should be fire-and-forget through a message queue. This separation is the single biggest performance win in the entire design.
- Your reasoning process matters more than the final architecture. Interviewers evaluate how you make trade-offs between consistency, availability, and complexity -- not whether you can recite a perfect system diagram from memory.
Your Next Steps
System design skills aren't built by reading - they're built by doing. Start by actually implementing a simple URL shortener. You don't need to build bit.ly, but create something that can shorten URLs and redirect them. You'll quickly discover problems this article didn't cover: How do you handle database migrations? What happens during deployments? How do you test a distributed system?
Once you've built something, practice explaining it. Set a timer for 45 minutes and design it on a whiteboard or paper. Can you cover all the important aspects in time? Can you explain your decisions clearly? Would someone who hasn't read this article understand your design?
Read real engineering blogs from companies like Uber, Airbnb, and Netflix. But don't just read them - think critically about their decisions. Why did Uber choose that particular database? What trade-offs did Airbnb make? How would you have solved the problem differently?
Most importantly, remember that in your interview, you're not just designing a URL shortener. You're demonstrating that you can think systematically about complex problems, make informed technical decisions, and build systems that work at scale. The URL shortener is just the canvas - your engineering judgment is what's being evaluated.
Master this design, understand the principles behind it, and you'll be ready to tackle any system design question they throw at you. Because once you understand how to think about distributed systems, the specific problem is just details.
Quick Reference: Numbers Every Engineer Should Know
| Operation | Latency | Notes |
|---|---|---|
| L1 cache reference | 0.5 ns | |
| L2 cache reference | 7 ns | 14x L1 cache |
| Main memory reference | 100 ns | 20x L2 cache |
| SSD random read | 150 μs | ~1,000x memory |
| HDD seek | 10 ms | 20x SSD |
| Network: Same-region RTT | 0.5 ms | |
| Network: Cross-continent RTT | 150 ms | |
| Network: 1 MB over 1 Gbps | 10 ms | |
| Database: Read 1 MB from memory | 250 μs | |
| Database: Read 1 MB from SSD | 1 ms | 4x memory |
| Database: Read 1 MB from HDD | 20 ms | 20x SSD |
Want to ace your next tech interview? See what 50,000+ engineers are raving about by signing up for Firecode